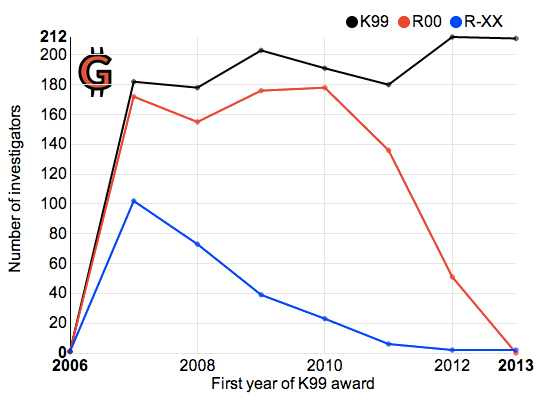
Not sure what to do with the graphs? Check our blog for latest discoveries in grantomics:
Or e-mail info@grantome.com and suggest new type of analysis.